Thu, Sep 7, 2017
I’m working on a plugin to caddy that hooks in hugo with a more tailored interface than its predecessor. The code is at: git.stephensearles.com/stephen/caddy-hugo2. I wrote a bit about why I chose to do this on the blog it was originally meant for, danandstephen.net, but I’m going to elaborate a little more here.
The thought process went roughly like this:
The requirements:
- Easy for me and my partner to manage and edit
- This means it needs to be GUI/web friendly with a WYSIWYG feel to the authoring
- Needs to support pictures, RSS, and basic blogging features
- Reasonably secure. This isn’t a bank blog, or anything, but at least not obviously vulnerable to like a light breeze.
- Low power; I want this to run on a cheap virtual server.
- Nice to have: written in Go, making it extra cheap and also easy for me to hack around on
Okay, so what choices are available?
- Blogger, medium: proprietary and not self-hosted. Those can be fine choices for people without some of the more custom options, but I think I can do better.
- Wordpress: huge and difficult to secure. I’ve been down that road plenty, so let’s not use that…
- Drupal, etc: huge, unfamiliar to me, and still not static (as far as I understand), and so the cost to run it sounds like it’d be an issue at some modest scale
- Jekyll, ghost, etc: static! But now we’re getting into the world of developer focused systems where the GUI is a question
- hugo … this is a static site generator written in Go. I have enjoyed it before, so using this would be nice. There’s even a plugin for an interface into caddy! .. Unfortunately, that plugin’s interface doesn’t provide any niceties for a WYSIWYG experience at all. It’s basically a wrapper around a file manager. … So what if I could replace that?
My thought process brought me about this far and I figured I’d give it a shot to link up hugo with a web WYSIWYG-ish markdown editor, contained in a new caddy plugin. It’s not just a good fit for our needs, either. I think this plugin bridges caddy and its goal of being a simple webserver for technical and non-technical people alike to publish on the web. It reduces the friction to getting accessible CMS features under a modern and automatic HTTPS server.
A few months and a few thousand miles later, me and my partner have been able to use it to host our Farm and Adventure blog. The project is coming along nicely. It’s got, so far:
- author overview page
- collaborative editing (deltas syncing via websocket)
- draft presentation alongside the edit screen
- image upload and serving, with on-the-fly resizing
- comments, optionally guarded by a low-security password
- definitely a few bugs
I’m going to keep working on it, but the source is already available if anyone else wants to try it, hack on it, or just watch.
Mon, Oct 27, 2014
Upfront, I’m going to point out that I have a horse in this race. In my experience, I’ve been bitten by gnarly, expensive code one too many times. That said, there’s been a few posts recently trying to suss out the difference between the two.
One of the pithy phrases that’s been going around:
A framework calls your code, you call a library.
This is so tempting, because it paints such a bright line. The truth is, though, the terms are ambiguous and have been used to describe such varying things in the past.
Apple uses “framework” to describe their various API groups, e.g. CoreLocation.framework, VideoToolbox.framework. C programmers have been using “library” for decades to describe the C equivalent of packages. The term “standard library” seems to mean “a lot of libraries that are part of a language distribution.” Wikipedia lists jQuery and Google Web Toolkit next to each other as Javascript frameworks. They are probably about as similar as the mercury in a thermometer and the water in Lake Superior. Sure, they’re both code for doing things on the web, but in one of them, you write almost exclusively in Java and the other just gives you some DOM and ajax tools.
We’re past the opportunity for a succinct definition for these words. A related issue, I probably read (or write) these words more often in posts deriding “frameworks” in favor of “libraries” just about as often as I read a post about a framework or library. With the current state of the field, I’m afraid I’ve come to the following conclusion:
The words “framework” and “library” are not meaningful on their own.
They both encompass “a distinct codebase you use from a project to avoid work duplication or to simplify a problem.” Perhaps you’ll say, “but they have different shades of meaning,” and perhaps they do to you. Just like the terms “web scale,” or “object-oriented,” or “the cloud,” they just aren’t specific enough. Write better than that; either avoid them or qualify them.
Now I don’t want to just leave you hanging, and as I said, I do have my stake here. Let’s take another look at some ideas people describe when they smack-talk “frameworks,” however, my critique here is just as valid for something called a “library.” Think of a common code dependency you like or dislike and answer these questions:
- Does it hide details about underlying actions in a way that makes it difficult for you to uncover them?
- Does it hide details about underlying data in a way that makes it difficult for you to compose its functionality with that of a similarly purposed “framework” or “library”?
- Does it lead to difficult to understand stack traces?
- Does it require a substantial amount of specific code (including configuration or subclasses) before it is useful?
- Does it require you to force your program’s structures or types into a pattern they don’t mesh with fluidly?
- Does it reduce the safety of your code?
- Does it make your code difficult to reason about?
- Does it limit your ability to provide features using patterns it doesn’t support?
- Does it encourage your own code to conflict or race with itself?
Great. Now consider the combined penalty of those “yes” answers. Other questions you can ask:
- How much are you gaining from this library?
- Is there another framework that could be a reasonable alternative?
These are the kinds of questions you can use to think about the quality of a project, rather than “is it a framework or library?” Because those words say nothing more than the fact it is a project, when you’re writing about it, let’s use words like the following to describe projects that answer “yes” to the above questions:
- expensive, ill-fitting, lossy, opaque, rough, encumbering, high-touch, gnarly, captive
and these to code that answers “no”:
- thrifty, frugal, tailored, concise, transparent, precise, straightforward, honest, agreeable, detachable
These are just some ideas. I’m looking forward to reading some well-worded reviews and critiques.
Sun, Aug 24, 2014
Useful info for new Gophers
A couple folks have had some questions for me about getting started with Go. I’m going to outline some of my favorite links for people to get familiar with the language and its fine idioms.
First stop: the Go tour. It takes roughly five hours and is a remarkably complete introduction to the structure of the language.
Critical documents:
The spec. It is well written and easily read. It’s plain english. I highly recommend bookmarking the spec as a go-to reference. What are the rules for low:high:max slicing again? It’s in the spec.
Effective Go. This is one of the earlier documents that describe the most well established idioms for the language.
Packages to look over:
These packages are some of the most often used and also some of the best examples of the standard library’s power. I recommend reviewing these and knowing well what’s in them.
http://golang.org/pkg/net/http/
http://golang.org/pkg/io
http://golang.org/pkg/fmt
http://golang.org/pkg/bytes
Here’s a few posts with good tips:
http://blog.natefinch.com/2014/03/go-tips-for-newbie-gophers.html?m=1
http://dave.cheney.net/2013/11/14/stupid-go-declaration-tricks
https://filippo.io/why-go-is-elegant-and-makes-my-code-elegant/
Here’s a few posts with more in-depth discussions to help you better internalize some Go features:
http://blog.golang.org/slices
http://mwholt.blogspot.co.uk/2014/08/maximizing-use-of-interfaces-in-go.html
http://dave.cheney.net/2014/03/17/pointers-in-go
http://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
http://jmoiron.net/blog/crossing-streams-a-love-letter-to-ioreader/
Sun, Aug 24, 2014
This will be a page I’ll revise from time to time: See here
Sun, Jul 27, 2014
There’s a lot of PHP out there. The problems plaguing that language are well documented, but many companies and projects are frightfully entrenched. There have recently been projects aimed at improving performance and reliability: things like Hack, php-ng, and the recent effort toward a language specification. Unfortunately, none of these projects will directly result in improving large, existing bodies of PHP. So when I learned Go, and I watched Rob Pike’s talk on writing the text/template lexer, I thought it would be fun to try out that language and idea on reading PHP. Over the past several months, that whim has evolved into a nearly feature-complete PHP parser.
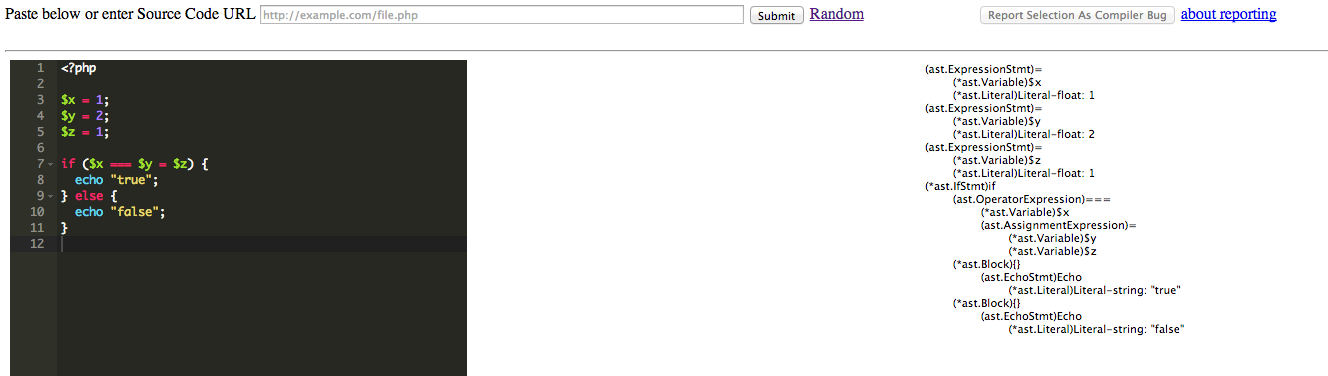
Until now, the goals and milestones related to this project have been nebulous at best. It began as a crazy experiment, after all. It currently parses most of the code I throw at it, with support for most PHP 5.4 features, but not all. Thus, the most important goal at this point is to move the parser further to solidly support the full set of PHP 5.6 features. As a stretch, it would be great if it was possible to set the parser to check against specific PHP versions. The project currently has 85% test coverage and 67% coverage with full unit tests, but I’d like to increase those numbers. I’d also like to improve stability when parsing incorrect code.
At this point, I think there is an opportune moment to consider the next direction to take the parser beyond just parsing. Here is a list of ideas I have:
- A phpfmt tool (a la gofmt)
- Static analysis tools (e.g. type inference, dead code detection)
- Transpiler
The transpiler is perhaps my favorite idea, particularly in Go. With the go/ast package, transpiling into Go is perhaps the closest in reach of all these goals, despite sounding so lofty.
All that said, this project began as an experiment, and for the time being, it continues as one. I’m happy to open up the project to a wider audience. Please feel free to comment or contribute. If you would like to just play with the parser, I have this little tool for testing. The code is available on Github.
Fri, May 16, 2014
TL;DR: Martini makes Go magic, but the whole point of Go is to be simple and not magic. It’s the wrong direction for the language and ecosystem, so try something like muxchain instead.
Sorry codegangsta; I really tried to write this post without calling out Martini, but the point just wasn’t coming across.
Martini has gained a tremendous amount of attention in a short time. I think it might have even gotten a few people to give Go a try. I think you shouldn’t use it and I have several reasons.
- Martini defeats the Go type system
Martini uses dependency injection to determine what your handlers are and how to pass requests to them and get responses back from them. Martini allows you to pass anything to its dependency injector and call it a handler.
Take a look at this code:
func main() {
m := martini.Classic()
m.Get("/bad", func() {
fmt.Println("Did anything happen?")
})
m.Run()
}
We’re going to revisit this example later, but this compiles, runs, and does almost what you’d expect. The gotcha, though, is that you would never want to do this, and appropriately, net/http would never allow it. That misstep is providing a handler that has no way of writing a response.
Another example:
func main() {
m := martini.Classic()
m.Get("/myHandler", myHandler)
m.Run()
}
var myHandler = "print this"
Does this work? Answer: sort of. It compiles, which should indicate it works. However, as soon as you run it, it will panic. Since the typical use case will be to set up handlers during initialization, this might not become a significant pain point for actually specifying handlers, but this is a real problem for the dependency injection package that’s part of Martini. This is abusing reflection so that you can defeat the compile-time type system and if you use it, it’s only a matter of time before it bites you. Moreover, the type system is a huge reason for choosing Go, so if you don’t want it, maybe try Python with Twisted.
- Martini defeats one of Go’s best patterns: uniformity and discoverability through streaming data
Say you’re new to Go. You have some images you’d like to serve on the web. This perfectly valid code seems like a reasonable, if naive, approach:
func main() {
m := martini.Classic()
m.Get("/kitten", func() interface{} {
f, _ := os.Open("kitten.jpg")
return f
})
m.Run()
}
What do you get in the browser? <*os.File Value> Wrong. So we try again.
func main() {
m := martini.Classic()
m.Get("/kitten", func() interface{} {
f, _ := os.Open("kitten.jpg")
defer f.Close()
i, _, _ := image.Decode(f)
return i
})
m.Run()
}
Now we get: <invalid Value>. What? You can dig into what Martini is doing with reflect to fully understand why this happens, but it suffices to say that this happens if you return an interface type from a handler to Martini. It is conceivable that someone would write a handler returning the empty interface, as I have done here, and sometimes return a correct type to Martini, but in some rare case, return something invalid. That sounds like a potential production issue, and makes Martini a risk.
So we try again and finally we got it.
func main() {
m := martini.Classic()
m.Get("/kitten", func() interface{} {
f, _ := os.Open("kitten.jpg")
defer f.Close()
b, _ := ioutil.ReadAll(f)
return b
})
m.Run()
}
This works. We finally got the image. Careful readers will notice out what’s terribly wrong here and why this anti-pattern should be avoided. All of the image is read into memory before being returned. If we took this approach with say, a large movie file, well, we might actually just run out of memory on the first request.
Others have written about Go’s inheritance of the Unix philosophy, but Martini makes it deceptively easy to throw that baby out with the bathwater. Yes, yes, you can just pass an http.Handler to Martini, but if you don’t always do that, we still lose the uniformity of our handlers (see the above point on types) and the discoverability of io.Reader and io.Writer beauty. To show you what I mean, here’s the handler I would have written:
func main() {
m := muxchainutil.NewMethodMux()
m.("GET /kitten", func(w http.ResponseWriter, req *http.Request) {
f, _ := os.Open("kitten.jpg")
defer f.Close()
io.Copy(w, f)
})
http.ListenAndServe(":3000", m)
This way, the io does all the work for me and uses only a small amount of memory as a buffer between the image and the network. Because io.Reader and io.Writer are used throughout the standard library and beyond, you end up being able seamlessly tie together things like images, encryption, HTML templates, and HTTP. It’s wonderful and it’s probably one of the biggest unsung heros of Go. However, HTTP is probably the most commonly used case. It’s how I discovered how awesome this is. Let’s not hide it, and let’s definitely not break it.
- Martini is broken
package main
import (
"fmt"
"github.com/go-martini/martini"
)
func main() {
m := martini.Classic()
m.Get("/", func() string {
return "hello world"
})
m.Get("/bad", func() {
fmt.Println("Did anything happen?")
})
m.Run()
}
The /bad route prints to stdout, but logs a status code of 0 (no response) while it actually returns a 200. What should it do here? That’s unclear, but the 200 response is default net/http functionality and the 0 response is inconsistent.
Ok, given this code:
import (
"io"
"net/http"
"github.com/go-martini/martini"
)
func main() {
m := martini.Classic()
m.Get("/+/hello.world", func(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, req.URL.Path)
})
m.Run()
}
what would you expect to happen if you browse to /+/hello.world? Yes, that’s right, a 404. Ok, now how about //hello.world? That one works. Have you figured it out? Martini is interpreting this as a regular expression. This is an inherent flaw with Martini as a Go package. Because you’re passing Martini this string and it might be a regular expression, but it might not, and some regular expressions are valid URL paths, there’s potential for conflict.
Conclusion
This post isn’t really about Martini. I singled out that package because I keep seeing it everywhere and have to keep asking myself why. I understand that it provides a great deal of convenience, but it does so with magic that comes at an even greater cost. One could see a future where many packages repeat these mistakes, pollute the ecosystem, and lead to difficulty in finding packages that don’t compound bugs like I have pointed out. This is not a good direction for us to take with Go. The wonderful thing, though, is that you don’t need it. I wanted to prove this to myself, so I wrote the muxchain package. Between that and muxchainutil, I have provided nearly every feature Martini provides, but with no magic. Everything is literally net/http, and there’s no reflection. Give it a try and tell me what you think. It’s new and might need some work. Most of all, I’m sure the naming could use some improvement. (Codegangsta: credit where credit’s due, that’s one thing you totally got right with Martini, so if you have any suggestions, please let me know.)
Sat, Dec 14, 2013
I recently found instructions from Dave Cheney on installing godoc as a launch agent in OS X. It’s really cool to have Go’s documentation running locally and to have the system ensure it’s always running for you, but I realized you can get it to display your own packages as well.
It’s insanely helpful to have documentation auto-generated for my packages that are consistent with and as nice as the documentation for the standard library.
This requires only a slight tweak in Dave’s file, adding your GOPATH as an environment variable (toward the bottom):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>org.golang.godoc</string>
<key>ProgramArguments</key>
<array>
<!-- ensure this is the absolute path to your godoc install -->
<string>/usr/local/go/bin/godoc</string>
<string>-http=127.0.0.1:6060</string>
</array>
<key>Sockets</key>
<dict>
<key>Listeners</key>
<dict>
<key>SockServiceName</key>
<string>6060</string>
</dict>
</dict>
<key>KeepAlive</key>
<true/>
<key>EnvironmentVariables</key>
<dict>
<key>GOPATH</key>
<!-- ensure this is your absolute gopath -->
<string>/Users/Stephen/Code/go</string>
</dict>
</dict>
</plist>
Simply install that to ~/Library/LaunchAgents/org.golang.godoc.plist, and run:
launchctl load ~/Library/LaunchAgents/org.golang.godoc.plist
Now navigate to http://127.0.0.1:6060 and see all of your own code alongside the standard library.
Searching
If you want to enable search, it’s just a small tweak to that file. Add this line just below the http flag:
<string>-index</string>
(You can also play with adding the index_throttle flag if you want that to use less cpu or finish quicker.)
I have found that once the index is created, it never gets updated. So to refresh the search index, kill the godoc process (launchd will restart it).
Mon, Dec 3, 2012
I’ve put a bit of time into the Park and Ride Maps app over the past few weeks. I pushed the latest update tonight. You can try it here: http://stephensearles.com/parkandride.
Other than a few stylistic changes, you’ll see I added a way for you to specify a park and ride stop. I found the app was not proving very useful for many of my searches because it just wasn’t finding great data for transit locations. This update is the first step toward fixing that. The next step is to use the Google Places API to add these locations to the database. It’s an exciting feature of that API and I look forward to the improvements user-generated data will offer applications like mine.
That’s it for now. Feel free to peruse the code or contribute to the project over at Github.
Sun, Nov 18, 2012
I released park and ride directions about a week ago. It’s a work in progress, but it definitely works in some cases. A few improvements I plan to make:
- The data source (Google Places API) doesn’t have every station listed, so I would like to modify the app to allow users to enter their own Park and Ride station. They’ll get directions using it, but then the new station will also be added to the Places database. Every time a person uses one, the place will get a “place bump.”
- The algorithm to decide where to check for park and ride stations doesn’t always return great results. I think this is because the Places API is only using my query as a guide, rather than a limit, to return results. I could do my own tests with the returned results and display a subset I think would be most helpful.
- It would also be neat to find plain driving directions and public transit directions, and alert the user if one of those would actually be faster. With driving, though, one of the benefits of park and ride is usually that parking at the station is easier than parking at your final destination.
There’s definitely interesting work to do here and I hope to revisit the project soon. The source is available on GitHub for any interested in contributing.
Sun, Apr 1, 2012
I did some thinking about managing such a big project like Chrome when it depends on such a big project like Webkit. Tons of Chrome bugs are actually Webkit bugs, or are related to Webkit bugs somehow, much like the one I encountered in my previous post. The Google Code project hosting doesn’t seem to have a great way to manage external bug dependencies not on Google Code as of yet, so I took it upon myself to write a tool to help Chromium developers find relationships between Chromium bugs and Webkit bugs. It’s a bit of Python and Javascript. I’m planning on releasing the source code soon, but the results are already online at http://stephensearles.com/chrome-webkit-bugs.
Just from the bit I’ve explored, there’s some rather astonishing findings. First of all, it looks like in virtually no case is there an open Chrome bug with a Webkit relationship that has been updated or commented upon more recently than its Webkit bug. This isn’t to blame the Chromium developers, because they’re likely fixing many of the Webkit bugs, rather, it’s a pleasant observation that when problems occur with Chrome, its developers seem to generally fix it at the source instead of writing some ugly workaround. That’s one possibility. Another observation is that many open Chromium bugs related to Webkit bugs, almost half of the ones I pseudorandomly looked at, are simply left open after the Webkit bug has been fixed. Sometimes for years. At least one of these required more work after the Webkit bug had been fixed, but presumably many many don’t. We’re talking about, if these statistics hold, 300 bugs that could just be closed right now. When was the last time the Chromium bug tracker had that good of a day?
Speaking of the Chromium bug tracker, if you take a close look at this scraped data, sort by the last updated project and you’ll find that there are some that have Chrome marked as their most recently updated, but because there are no Webkit bugs! How did this happen? Well, two things, and two potential issues in Google Code. First, there’s a little issue with how Google Code displays comments. It wraps them all in
tags, which is how Google Code seems to display HTML source. Pretty common for talking about a browser. When it linkifies URLs, however, it makes errors when the URLs are wrapped. In the cases I’ve seen (example), it’s happening about the “?” of the query parameter, so it could be a regular expression error or something to do with anchor elements inside pre elements. The second Google Code bug is more nebulous to me. If you look at those roughly 40 bugs with no Webkit bugs referenced in the list, many of them actually have no Webkit bugs referenced in them! This surprised me, because to get my list, I’m using Google’s search. My query exactly is “bugs.webkit.org/show_bug.cgi”, and though I’m using the API, it’s curious why Google’s search is returning, what seems to be, false positives. Looking closer, the bugs referenced usually have some other bug tracker with a “show_bug.cgi” link, so it’s just using the slash as a word boundary and searching the two sections independently. This is something I could likely address with more clever searching and data processing, but I also wonder if there’s a literal search option that’s just not made obvious. So if you know anyone who works on Google Code itself, things to look at…
So I hope this helps out someone working on Chromium. Give me a shout if you find it particularly useful or if you have ideas for expanding it. I’m thinking about a few things like an auto-commenting bot (which may be too intrusive) or an RSS feed. I’d love to hear any thoughts. It seems like there’s so many simple things that could be fixed, or at least kept tabs on better, with a bit more information.
Tue, Mar 13, 2012
So I recently became an author of Chromium. I fixed a very minor bug, one that’s sort of overshadowed by a larger one. I’ll get back to the specifics, but I’d like to first say, what a fun experience. Chromium is definitely the largest project I’ve ever contributed to, mostly because I’ve avoided it. Learning the process, getting acclimated to a huge code base; these are things I’ve needlessly feared. Yes there’s things to learn, and yes, finding the location of your bug in the code is like sailing for buried treasure when your map only has the names of the islands. But it is a treasure hunt that comes with both satisfaction and rewards.
I would say the most difficult part about getting involved is the mechanics of managing the source. Obviously—it’s huge. It takes the better part of an hour to download the git repository, if not more. The first compile takes just as long and each one thereafter is nothing to scoff at, especially if you’re accustomed to the browser-refresh build time of web development. That said, there’s some pretty neat tools the Chromium developers have to manage it. I was most impressed by bisect-builds. Think git bisect, but if git were to serve you revisions to try like an attentive waiter serves courses. Like git proper, it chooses the revisions and helps you narrow down to the one introducing the bug, but it also seamlessly manages downloading and preparing built versions of Chromium, in the background, so you won’t even need to wait in many cases. All it needs is a good sommelier plugin.
In the abstract, the review and commit process had me spooked too. I could just imagine some snippy programmer getting on me for curly braces in the wrong spot or for not saying the right thing in a commit message. Yes, style is important, especially in such a big project, and yes, style guides can err toward the ridiculous, but no, it’s not something serious to worry about. I didn’t end up doing anything that would likely get me into trouble, but even if I had, that’s the reason these processes are in place. The key here is patience. With a project like Chromium, there’s tons of developers employed to work on the project and they tend to be helpful because they know the process can be daunting to newcomers. They, after all, were newcomers at one point and they probably made more mistakes than they’d care to tell you.
Now to the actual code. My biggest impression here is organization. There was lots of it. Not all of it made sense to me, but there it was. Everything goes in src. WebKit goes in third_party. HTMLSelectElement goes in html. It’s great that there’s some system in place, but it was pretty much completely useless to me. The bugs I grappled with had to do with click events not firing for select elements, but only on the Mac. I traipsed through directory after directory, breaking things just to get stack traces, doing anything I could to leave some semblance of a breadcrumb trail. This is the biggest epitaph that ever could be for Code Search. Google notes that, “Much of Code Search’s functionality is available at Google Code Hosting including search for Chromium,” so I got to use what’s left of it working on these bugs, but for other large projects, similar tasks must be horrendous. You’d think the company that tasked itself with “organizing the world’s information” would see it vital to organize the information we use to organize information. (Yo dawg…)
As for the bug itself, if you take a look, you’ll find an interesting example of ways cross-platform applications interact with specific platforms. Mac users, did you ever notice that the little menu that pops up with select boxes is the same in most programs? That’s because even programs not mainly written in native Cocoa can still call out to it so they can provide a native-appearing interface. Such complexity can result in hiccups like onmouseup events not firing for select elements, because by the time the mouse button is released, the cursor is no longer in the purview of the select, but an NSMenu offered by the OS. The problem was solved in WebKit2 by firing a fake event, tricking the select into thinking its click was finished, but the fix never made it into the regular WebKit source used by Chromium. I haven’t quite figured out how to patch that up just yet, but the commit I did make fixed a related issue Chrome itself had on the about:flags page. Presumably this isn’t the only place seeing the problem; you can see it for yourself here.
I plan to keep working on that bug. If you, dear reader, write the patch before me, more power to you, there’s over 30,000 open bugs. (At the time of this writing—let’s get cracking!) It really was a lot of fun, and if you need any help getting started, there’s a bunch of resources, a helpful Chromium team, and definitely feel free to shout out to me and I’ll do my best to give you a hand or help find someone who can.
Wed, Jan 25, 2012
Git is incredibly handy for moving work around to different machines, so a reasonable thing to consider is actually deploying a website to your server. I’ve done this in a few different ways, but this is a simple recipe to accomplishing the task. In these steps, I assume you’ve already SSH’d into the server and you know where your web root is.
-
On the server, outside of the web root:
mkdir myRepo.git
cd myRepo.git
git init --bare
-
On the local machine:
git remote add myServer myUsername@ServerHostname:~/path/to/myRepo.git
git push myServer master
The name for your remote can be whatever you want, but the server hostname needs to be what you use to SSH into your server. The way we’re setting this up, unless you have SSH certificates already installed, this process will ask you for your password every time you attempt to push something up to the server.
-
Back on the server, in the web root, at the location you want the website to be deployed:
git clone ~/path/to/myRepo.git .
-
And then, to make the live repository auto-update, you need to modify the hooks/post-receive file in the bare repository. You may need to rename it from post-receive.sample, but this is what it should contain:
cd /absolute/path/to/myLiveDir
env -i git pull --ff-only origin master
env -i git submodule sync
env -i git submodule update --recursive
The reason for those last two commands is so your submodules, if you have any, will remain in sync and checked out on the deployed repository. You might also need to change the permissions on this file, if they’re not already correct:
chmod 755 post-receive
And you’re set. All you need to do to push new commits to being live on your server is:
git push myServer master
For those interested, what’s happening here is that you’re pushing to a repository on your server. It’s a bare repository, so it only contains the git object version of your files. This repository, however, upon receipt of new commits, will push them to a regular repository in the web root. The reason to have essentially a proxy repository is because, without overriding some protective settings, git disallows updating a non-bare remote repository:
Refusing to update checked out branch: refs/heads/master. By default, updating the current branch in a non-bare repository is denied, because it will make the index and work tree inconsistent with what you pushed, and will require ‘git reset –hard’ to match the work tree to HEAD.
So, setting up this proxy allows you to keep this setting intact. Further, because we told git to only allow fast-forward updates, we have to resolve any potential merge conflicts before the live repository will accept any changes. It’s pretty simple to stay ahead of this, just don’t make any commits directly to the live repository and always reconcile with the bare repository before attempting to push.
Related to this and the topic of a planned post, you can use a similar strategy to version and synchronize a database schema. It’s definitely a more complicated, and somewhat riskier process, but one that deserves some attention soon.
Sun, Jan 22, 2012
I recently switched to Chrome in celebration of Tyler joining the Chrome team at Google, and it’s been really great. The Omnibox is perhaps one of the best features, but the experience out of the box did leave some things lacking.
As a user, I often visit websites and bookmark them to save them for later reference, or I don’t, and I just expect to be able to find it in the browser history. This seems pretty standard. My thought is that the Omnibox should be more helpful in this process. Sure, I could just search again or use one of the few history or bookmark suggestions that pop down, but sometimes I really just want to get a quick search within the scope of things in my history or bookmarks, perhaps with the ease of a search engine keyword. Fun fact, you can do this! It just takes a little digging into the Chrome settings.
So, say you want to be able to type “h javascript” to search your history for anything Javascript, simply go to your search engine settings (chrome://settings/searchEngines). Here, you can add History with “h” as the keyword and the following as the URL:
chrome://history/#q=%s
You can do the same for bookmarks with:
chrome://bookmarks/?#q=%s
Perfect. Now if only this were a more noticeable option, perhaps as a default setting; I’m sure other people would love this were it more obvious.
Sat, Jan 21, 2012
Through all the protest around SOPA, one tweet prompted thoughts about the overarching role of technology:

The motivation behind this statement reflects a systemic misunderstanding of the Internet’s role in our dramatically changing society. It seems to me that it is either a refusal to adapt or an ignorance of the need. The academic exercise this tweet describes has, in some respects, become irrelevant. The skill to find information about a well researched topic becomes more and more trivial as Wikipedia and Google’s search index grow.
If the task Lamy thinks we’re not teaching students is original research, then have them contribute to one of the thousands of stub articles on Wikipedia. Or have them improve an existing article that lacks bibliographic support. To simply cut off modern tools from students to deliver the same education their parents got will only prepare them for the world their parents inherited, not the ones they will. Because in most practical situations, these tools will be available, to teach research skills independent of them is meaningless. As with fields beyond education, the solution is clear—embrace technology and retool or stifle those you serve with your ignorance—not something people tolerate for long.
Tue, Oct 18, 2011
I recently (mostly) finished a transition to a new server. I came from a free web host that was pretty good, but had some significant limitations (mainly in PHP, but also that I was limited to software they provided). Now I have my own VPS. I struggled a bit getting set up, but now I’m much better from it. To someone getting started on this kind of project anew as I did, here’s a few pieces of advice:
- Use an OS that has a package installer. SSH and SFTP are great, but they are only minimally convenient when it comes to installing lots of software. When you consider every little thing you’ll end up needing (which is a lot—my server didn’t even come with cURL installed), having an easy way to get all these little things is vital to your sanity.
- Consider the software you’re planning to use. Not doing this is a mistake I have yet to pay for. As I type this, I’m using Lighttpd as my webserver. Because I’d like to deploy an instance of Diaspora*, I’m likely going to need to switch back to Apache or some more conventional server. The issue is Lighttpd will not allow some of the server to be on http and some of it to be on https. It’s all or nothing. I certainly would like parts of it to be on https, but not all of it should be. If I had known these things ahead of time, I could have prevented myself from duplicating a lot of work. On the other hand, I suppose these things must be trial and error for a while, unless you read every little detail beforehand.
- Set up a significant block of time to get your server up and/or make switching to your domain name one of the last things you do. For a while during the installation of various things (i.e. WordPress), the website, when visited, would display some confidential information. This is a problem. The suggestion here is that while these hiccups are difficult to avoid for a new sysadmin, minimizing the time and visibility of these issues can significantly mitigate the problem.
That’s it for now. Later to come: a step by step on how I now deploy parts of my site using git, because conventional knowledge didn’t seem to work for me and might not for you either.
Mon, Aug 29, 2011
After a long while, I finally have a working version of WebIAT online. I originally developed this for some cool folks over at the UCLA Anderson School of Management: Geoff Ho and Margaret Shih, but they graciously agreed to open source the work so I can continue working on it.
The software manages and runs Implicit Association Tests. These experiments, pioneered by Anthony Greenwald, determine a person’s association between different paired categories. They could be many things, but commonly they have to do with positive/negative and some class of people potentially facing discrimination, like black/white or employed/unemployed.
The version here is an early alpha, but it is up and running here: http://iat.stephensearles.com/admin/. The current login available publicly is username: test password: test. This will change soon. Further, any data on the site could be wiped off as I continue to develop, so don’t put anything there you’re counting on. Other than that, let me know what you think! Play with the site, and if you like, tinker with the source code here.
Mon, Aug 15, 2011
At the start of this blog, I would like to take a moment to outline my own expectations for what I plan to do here. The thought to start a website at all came from a need for a place to publish code and demos online. Done. Registered the domain and there’s already a bit of code here. The bigger question, though, is what can I do with this here website? What does it represent to me? Sure, the main thrust behind it will be to host my own code, but at the same time, I can use it to express more than my ability to write code.
I had always been hesitant in the past to start something like a blog. I worried about being held to the words I publish online. I feared the likelihood that nobody really has much interest in what I have to say. So why have a blog component to what could be a much simpler website? Despite all my concerns, I have a voice and I should use it. What more, it really is an exciting privilege that I can write these words on my own website. Now, I step into an emerging global conversation on the Internet on my own terms, not on those of any social media platform, not within the domain of anyone else. This is an important point, because in the era of Facebook, on the possible brink of a paradigm shift toward Google Plus, we need to remember that the Internet is more than the websites that are already there. We can take it back and reclaim it as the public and open virtual space it once was.
While I won’t hold myself to a particular topic for this blog, this post should be telling. Code and critical thinking will both be prominent. With that, I’d like to note that there is some code already here: jEditUndo and SelectWithOther.jEditable. Both plugins to an edit-in-place jQuery extension, developed for a much bigger project I’d like to talk more about very soon.